Posted: March 12th, 2011 | Author: chmullig | Filed under: Nerdery, politics | Tags: data, documentation, voter file | No Comments »
Political Data Nerds,
I’ve spent far, far too many hours of my life working with voter files. Every voter file sucks in its own unique way, and figuring out exactly how Montana sucks differently from Kansas is a unique and constant battle. Well, I’m tired of it! I don’t want to have to re-learn these challenges next time I work on a file, I don’t want to dig for the raw documentation (only to realize that it’s not always accurate).
I’m thinking of starting/contributing to a resource that consolidates documentation on all voter files out there. It wouldn’t be the data, it would just be freely available documentation to help anyone who’s already working with the data work with it more easily. What do you think?
I imagine it would have a list of vendors who provide these services as well, but the focus would be on helping anyone who’s trying to do it themselves. Probably should also have some more general tech recommendations, like how to concatenate files together, standardize addresses, geocode, etc.
Questions it would most definitely answer for every voter file (at least states, counties aren’t that important to me right now):
- Where can I request this, and how much does it cost?
- What format is it? CSV? Tab delimited text? Does it have a header? One file per county, or one per state?
- How is vote history stored?
- How do I translate from their geopolitical districts to something “standard?”
- How do I translate from their counties to county FIPS codes?
- What fields does it contain? Name? Address? Date of Birth? Phone? Party?
- Mapping their vote history to some more global standard (for the common elections).
This wouldn’t be doing anything for you, but hopefully it would ease the pain of anyone having to work with raw voter files.
Pew’s Data for Democracy report is an excellent start. However it’s a static and higher level document. I’d like a living document that contains more concrete information, and can be easily updated.
Does anyone know of an existing project doing this that I could contribute to? If not, are there any platforms better than Mediawiki to use? I’d rather not spend a lot of time writing original code for this, but that might be inevitable if I don’t want to do a ton of copy/pasting in mediawiki (boy does Mediawiki suck, too)…
No Comments »
Posted: February 23rd, 2011 | Author: chmullig | Filed under: Nerdery | Tags: graph, matching, mitre, python, r | 13 Comments »
For my own curiosity I created a python + R script to grab the MITRE leaderboard and graph it. It’s a bit of python to grab the leaderboard and write out some CSVs. Then a bit of R code (updated link: http://a.libpa.st/4KFGq) generates the graph. It’s running automatically with launchd on my laptop, and it should be regularly uploading a png to the address below. Launchd is pretty awesome, but a royal pain in the ass to get set up. It doesn’t feel very deterministic.
I still need to figure out how to jitter the names so they don’t overlap (like YouGov & Agent Smith), but other than that I thought it was a nifty little exercise.

Each line is a team, with their best MAP scores as datapoints
Posted: February 17th, 2011 | Author: chmullig | Filed under: Nerdery | Tags: programming, python, work | No Comments »
My illustrious former colleague Ryan is now over at MITRE doing operations research and who knows what. He pointed me toward the MITRE Challenge.
The MITRE Challenge™ is an ongoing, open competition to encourage innovation in technologies of interest to the federal government. The current competition involves multicultural person name matching, a technology whose uses include vetting persons against a watchlist (for screening, credentialing, and other purposes) and merging or deduplication of records in databases. Person name matching can also be used to improve document searches, social network analysis, and other tasks in which the same person might be referred to by multiple versions or spellings of a name.
Basically they give you a small list of target names, and a ginormous list of candidate names, and for each target name you return up to 500 possible matches from the candidate name list. Currently the matching software we built at Polimetrix back in 2005-2007 is doing pretty well. It was designed for full voter records, but I broke out the name component by itself. The result is pretty awesome. Currently we’re ranked #1 at 72.038. Below us are a few teams, including Intaka at 68.801 and Beethoven at 58.501.
No Comments »
Posted: February 9th, 2011 | Author: chmullig | Filed under: Nerdery | Tags: programming, stackoverflow | 3 Comments »
Recently I’ve gotten a bit obsessed with stackoverflow.com. It’s a programming Q&A site. You can ask questions, you can answer and comment on them. However they have a sick twist – people vote on everything. They vote on your questions, answers, comments. You earn reputation points when your content is voted up, and you lose points when it’s voted down. You also earn badges, like gaming achievements.
They’ve recently started a whole bunch of related sites under the stackexchange brand. Same model and software, but with different subjects. So far there are already more than I care to count with only very spurious differentiation, but a few highlights include gaming, cooking, english, programming (as a profession), power users, sysadmin, linux, ubuntu, and a lot more.
Here’s my badge of honor. Right now I have 674 rep and 10 badges on Stackoverflow, and 261/4 on gaming (plus ~100 on a bunch of the other sites, just for signing up). That’s my profile image, which should update automatically!

It’s amazing how satisfying and competitive the Q&A system ends up. I find myself less and less interested in any other medium for asking or answering questions like the kind on Stackoverflow. It’s slow and there’s no rep, what’s the point?
3 Comments »
Posted: November 11th, 2010 | Author: chmullig | Filed under: Nerdery | Tags: challenge, programming, python, r | No Comments »
I’m a fan of puzzles, programming and learning, so I’ve always enjoyed The Python Challenges. Recently my coworkers Delia, Chris and I came up with the idea of doing some of those within the company to help ourselves and our coworkers become more familiar with Python and R (and to a lesser extent SQL and other languages).
The end result is the YG Challenge, where we’ll be posting a few problems a week in at least R & Python, then solving them. Week 1 is up, and we have some great ideas for the future. Intended for our coworkers, it’s public because why not! Feel free to take a stab at solving them, especially if you haven’t used either of those languages before.
No Comments »
Posted: May 14th, 2010 | Author: chmullig | Filed under: Nerdery | Tags: pmxbot, python | No Comments »
As everyone is well aware, lunch is the most important part of the work day. However it’s often hard to find inspiration when deciding on a delectable dining destination. The ideal solution is to have someone propose options, and everyone reject them until consensus is reached. However nobody enjoys that. Computers can propose options, but that’s less social.
pmxbot has an existing !lunch command that’s supposed to help. Unfortunately you have to fill out the dining list yourself, and frankly, that’s a pain. The result is lots of old, bad definitions in a few limited areas. It does let you sneak in some comedy options (What to have in Canton? PB&J? Leftovers?), but for the main purpose it kinda sucks.
The solution is to use someone else’s database. I cooked one up yesterday pretty quickly using Yahoo Local’s API and the pYsearch convenience module. The result is quite easy, really. The only wrinkle is you need that module (someone could rewrite it to use just urllib and simplejson, if they cared) and a Yahoo API key.
The code is below, also available at http://libpa.st/2K0kh.
@command("lunch", doc="Find a random neary restaurant for lunch using Yahoo Local. Defaults to 1 mile radius, but append Xmi to the end to change the radius.")
def lunch(client, event, channel, nick, rest):
from yahoo.search.local import LocalSearch
location = rest.strip()
if location.endswith('mi'):
radius, location = ''.join(reversed(location)).split(' ', 1)
location = ''.join(reversed(location))
radius = ''.join(reversed(radius))
radius = float(radius.replace('mi', ''))
else:
radius = 1
srch = LocalSearch(app_id=yahooid, category=96926236, results=20, query="lunch", location=location, radius=radius)
res = srch.parse_results()
max = res.totalResultsAvailable if res.totalResultsAvailable < 250 else 250
num = random.randint(1, max) - 1
if num < 19:
choice = res.results[num]
else:
srch = LocalSearch(app_id=yahooid, category=96926236, results=20, query="lunch", location=location, start=num)
res = srch.parse_results()
choice = res.results[0]
return '%s @ %s - %s' % (choice['Title'], choice['Address'], choice['Url']) |
Posted: May 3rd, 2010 | Author: chmullig | Filed under: Nerdery | Tags: library paste, paste, pmxbot, python | No Comments »
The ever impressive Jamie wrote a nice little paste bin at work a while back. It was dead simple to use, relatively private (in that it used UUIDs and didn’t have an index), and hooked into pmxbot. Unfortunately like most of the code written internally it used a proprietary web framework that’s not open source. It’s like cherrypy & cheetah, but different.
I decided to modify jamwt’s pastebin to make it open sourceable. It’s now up on BitBucket as Library Paste. It uses cherrypy with Routes (NB: Must use routes <1.12 due to #1010), mako for templating, simplejson plus flat files for a database, and pygments for syntax highlighting. One of the great features is that it also allows one click sharing of files, particularly images. How handy is that?
For code – you specify a Pygments lexer to use and it will highlight it with that when displayed. You can leave it unhighlighted, and always get the plain text original.
For files – it will take anything. It will read the mime type when you upload it, and set it on output. It will tell your browser to display it inline, but it will also set the filename correctly so if you save it you’ll get whatever it was uploaded with, rather than the ugly uuid with no file extension.
There are a few minor improvements from the in house original. First, the upload file is on the same page rather than separated from uploading code. Second, it handles file names with spaces better. Third, there is no third.
I’d really like to get configuration/deployment setup. What’s considered a good, flexible way to to make it easy for folks to deploy an app like this? Use cherrypy config files, build a little bin script and optionally let folks run it behind wsgi if they want to nginx/apache it?
I’d also like to try with putting it up on Google App Engine. Looks like you have to jump through a few hoops to adjust code to use it, and I’d have to adapt the flat file system to use their DB.
One nifty “hidden” feature it has is that you can ask it for the last UUID posting for a given user, if they filled in the nickname. You simple visit http://host/last/user and get back a plain text response with the UUID. pmxbot can use this to provide a link to someone’s most recent paste. Here’s the generic pmxbot function we used.
@command("paste", aliases=(), doc="Drop a link to your latest paste on paste")
def paste(client, event, channel, nick, rest):
post_id = urllib.urlopen("http://paste./last/%s" % nick).read()
if post_id:
return 'http://paste/%s' % post_id
else:
return "hmm.. I didn't find a recent paste of yours, %s. Try http://paste to add one." % nick |
-
-
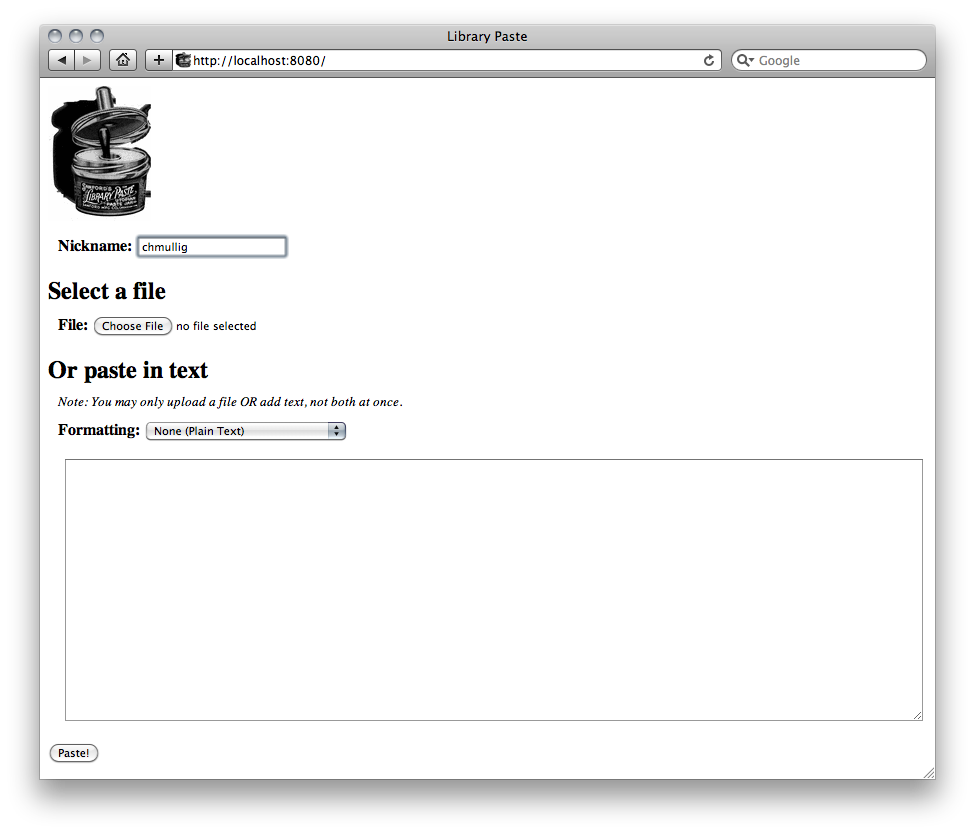
The input/home screen for adding a new paste. Earlier users note – file input on the same page.
-
-
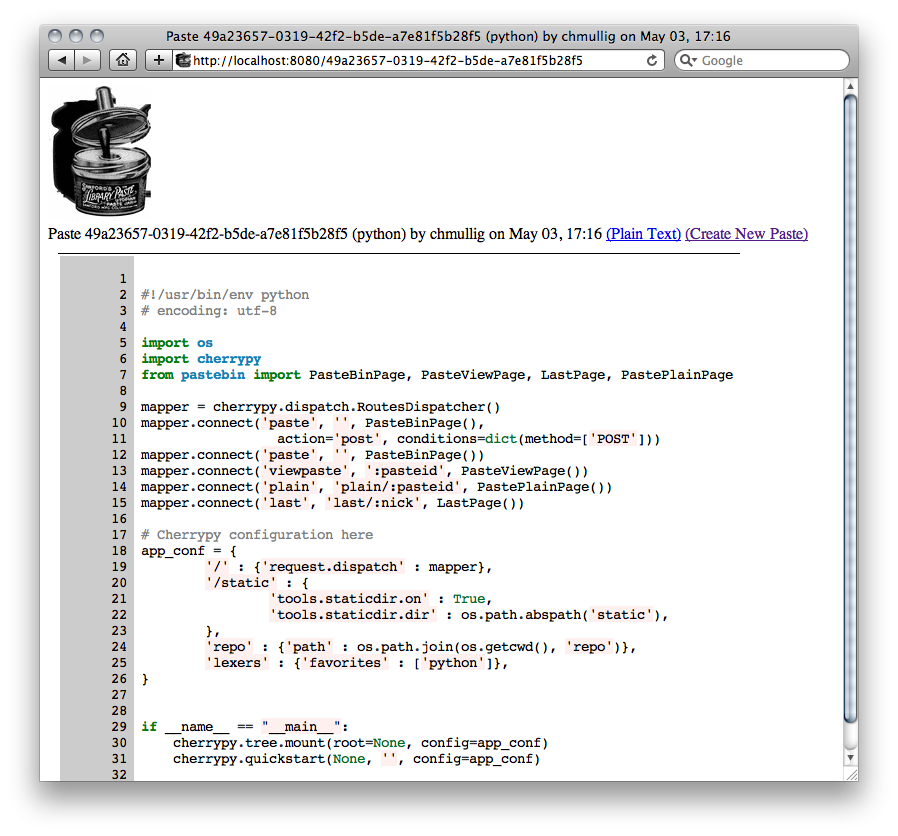
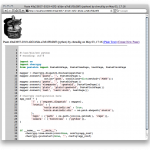
Showing some syntax highlighted code (indeed, Library Paste itself. The pastebin equivalent of boostrapping?)
-
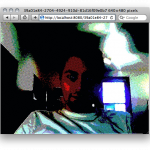
-
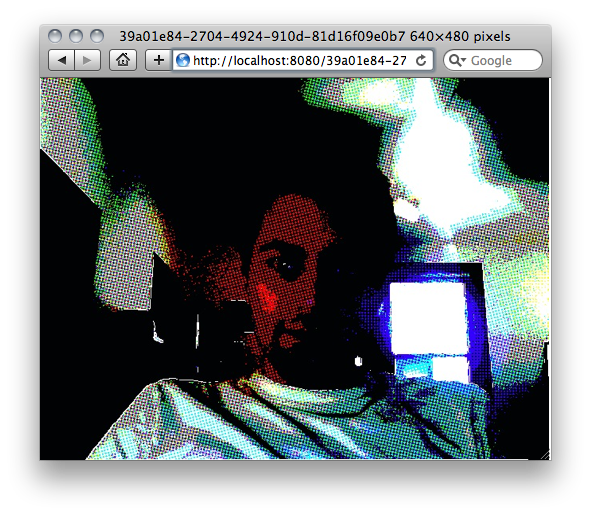
An image being served up by library paste. It automatically sets the mime type and filename based on what was uploaded.
Update:
I’ve since made a google app engine compatible version. It’s publicly hosted and you’re welcome to use it. http://librarypastebin.appspot.com and at http://libpa.st. Yes, I bought a stupid short URL for it!
No Comments »
Posted: April 7th, 2010 | Author: chmullig | Filed under: Nerdery | Tags: irc, pmxbot, python | 3 Comments »
My employer just open sourced a fork of the IRC bot we’ve been using internally for years, pmxbot. jamwt and some others are responsible for all the good parts of it, but I’ve been responsible for most of the feature bloat for the past few years. The open source version strips out internal code that or didn’t need to be shared, and overall makes it much more flexible for others to use.
It’s really a pretty great system, and I’m going to share some of the actions that we didn’t release, but that you might get some value or inspiration from. Of note, a few of these will reference internal libraries, so you’ll need to switch ’em to use urllib2 or similar.
The basic way you extend pmxbot is with two decorators. The first is @command, and the second is @contains. @commands are commands you explicitly call with “!command” at the beginning of a line. @contains is a very simple pattern match – if the phrase you register is in the line (literally “name in lc_msg”).
When you use the decorators on a function you’re adding it to pmxbot’s handler_registry. Every line of chat it sees will then be checked to see if an appropriate action exists in the registry, and if so the function is called. It goes through the registry in a certain order – first commands, then aliases, then contains. Within each group it also sorts by descending length order – so if you have two contains – “rama lama ding dong” and “ram” – if a line had “rama lama ding dong” it would execute that one. pmxbot will execute exactly 0 or 1 actions for any line.
The decorators are fairly simple – @command(“google”, aliases=(‘g’,), doc=”Look a phrase up on google, new method”). First is the name of the command “google”, which you trigger by entering “!google.” Second is an optional iterator of aliases, in this case only one, “!g.” You could have several in here, such as aliases=(‘shiv’, ‘stab’, ‘shank’,). Last is an optional help/documentation string that will be displayed when someone does “!help google”. The contains decorator is the same, but uses @contains and doesn’t support aliases.
A command is called when it’s picked out of the handler registry to handle the action. Any handler will be called with the arguments – client, event, channel, nick and rest. You can ignore client and event for 99% of cases, they’re passed through from the underlying irc library. Channel is a string containing the channel the command was made in. Nick is the nickname of the person who made the call. Rest is the rest of the message, after the command prefix is removed if it’s a command. For example if we saw the following line in #pmxbot: “<chmullig> !g wikipedia irc bots” the google function would be called with channel == “#pmxbot”, nick == “chmullig” and rest == “wikipedia irc bots”.
A basic command
Putting it all together, let’s look at a basic command – !google.
@command("google", aliases=('g',), doc="Look a phrase up on google")
def google(client, event, channel, nick, rest):
BASE_URL = 'http://ajax.googleapis.com/ajax/services/search/web?v=1.0&'
url = BASE_URL + urllib.urlencode({'q' : rest.strip()})
raw_res = urllib.urlopen(url).read()
results = json.loads(raw_res)
hit1 = results['responseData']['results'][0]
return ' - '.join((urllib.unquote(hit1['url']), hit1['titleNoFormatting'])) |
It registers the function google, under the command google, with an alias g. Note that the google function doesn’t have to match the name in the decorator, it can be anything. Within this function we can do anything you could want to do in python – we use urllib to call google’s ajax apis, and use simplejson to parse it and return the URL and title of the first hit. Anything returned or yielded from the function is passed back to the channel it was called from. If you want to have pmxbot perform an action, just return text that begins with “/me.”
Now let’s do a short contains example – simple enough.
@contains("sqlonrails")
def yay_sor(client, event, channel, nick, rest):
karmaChange(botbase.logger.db, 'sql on rails', 1)
return "Only 76,417 lines..." |
This one has no doc (you can’t get help on contains ATM) and it’s pretty simple. That karmaChange line increases the karma of “sql on rails,” but we’re not talking about karma.
Yahoo
You’ll need the BOSS library for this, and you’ll need to register an API key and put a config file where the library expects it. However it works fine once you do all that.
@command("yahoo", aliases=('y',), doc="Look a phrase up on Yahoo!")
def yahoo(client, event, channel, nick, rest):
from yos.boss import ysearch
searchres = ysearch.search(rest.strip(), count=1)
hit1 = searchres['ysearchresponse']['resultset_web'][0]
return hit1['url'] |
Trac
This is one of my favorites. We use Trac internally for ticketing. We have two commands that use the XMLRPC plugin for Trac to make it accessible for pmxbot. The first finds any possible ticket number (eg #12345) and provides a link & ticket summary. Note that we put a hack into the handler registry to make this the first contains command it checks, you could do something similar if you wanted to modify it.
@contains('#', doc='Prints the ticket URL when you use #1234')
def ticket_link(client, event, channel, nick, rest):
res = []
matches = re.finditer(r'#(?P<ticket>\d{4,5})\b', rest)
if matches:
tracrpc = xmlrpclib.Server('https://user:pass@trac/xmlrpc')
for match in matches:
ticket = match.groupdict().get('ticket', None)
if ticket:
res.append('https://trac/ticket/%s' % ticket)
try:
res.append(tracrpc.ticket.get(int(ticket))[3]['summary'])
except:
pass
if res:
return ' '.join(res) |
The second uses the RPC to search trac for a ticket or wikipage that might be relevant.
@command("tsearch", aliases=('tracsearch',), doc="Search trac for something")
def tsearch(client, event, channel, nick, rest):
rest = rest.strip()
url = 'https://trac/search?' + urllib.urlencode({'q' : rest})
tracrpc = xmlrpclib.Server('https://user:pass@trac/xmlrpc')
searchres = tracrpc.search.performSearch(rest)
return '%s |Results: %s' % (url, ' | '.join(['%s %s' % (x[0], plaintext(x[1])) for x in searchres[:2]])) |
Notify
This one is a total hack, but we were having issues with coordinating a certain team. We added a !notify command to help folks easily let everyone, online & off, know what they were up to. It simple sent an email to a distribution list.
@command("notify", doc="Send an email to list@domain.com, let them know you accidentally wiped a server.")
def notify(client, event, channel, nick, rest):
server = smtplib.SMTP('mail.domain.com')
notification = '%s: %s' % (nick, rest.strip())
try:
sigraw = rand_bot(client, event, '!notify', nick, rest)
if type(sigraw) == GeneratorType:
sigraw = '\r\n'.join(sigraw)
signature = '\r\n\r\n--\r\n%s' % sigraw
except:
signature = ''
msg = 'From: pmxbot@domain.com \r\n'\
'Reply-To: list@domain.com \r\n'\
'To: list@domain.com \r\n'\
'Subject: !notify: %s \r\n\r\n'\
'%s \r\n\r\n'\
'Hugs & Kisses,\r\npmxbot'\
'%s\r\n\r\n' % (notification, notification, signature)
server.sendmail('pmxbot@domain.com', ['list@domain.com',], msg)
server.quit() |
Invite
This one is a little weird, but as more people got on IRC we wanted to send them a little email to let them know how to access it, etc. It’s also useful to harass people who aren’t online, but should be.
@command("invite", aliases=('spam',), doc="Send an email to an invitee, asking them to join irc.")
def invite(client, event, channel, nick, rest):
server = smtplib.SMTP('mail.domain.com')
if rest:
try:
inviteText = rest.split(' ', 1)[1]
except:
inviteText = ''
invitee = rest.split(' ', 1)[0] + '@domain.com'
try:
sigraw = rand_bot(client, event, '!notify', nick, rest)
if type(sigraw) == GeneratorType:
sigraw = '\r\n'.join(sigraw)
signature = '\r\n\r\n--\r\n%s' % sigraw
except:
signature = ''
msg = 'From: pmxbot@domain.com \r\n'\
'Reply-To: noreply@domain.com \r\n'\
'To: %s \r\n'\
'Subject: join us in irc! \r\n\r\n'\
'%s \r\nRemember, you can find about irc here: https://intranet/IRC\r\n'\
'You can access IRC via your web browser at https://domain.com/irc \r\n\r\n'\
'Hugs & Kisses,\r\n%s & pmxbot'\
'%s\r\n\r\n' % (invitee, inviteText, nick, signature)
server.sendmail('pmxbot@domain.com', [invitee,], msg)
server.quit() |
Personal Responses
We have a ton of these, this is just one example. They watch for people being referenced, and occasionally (the randomness is key for many of them, to keep from being obnoxious) respond.
@contains("elarson")
def elarsonthemachine(client, event, channel, nick, rest):
if nick == 'elarson' and 'http://' not in rest and 'https://' not in rest:
return 'elarson - The Machine!!!' |
Other RPCs
I won’t show you the code, because removing the specific stuff would make it boring. But we have about a half dozen internal RPCs we can call with it. Some use Pyro, others XMLRPC. That trac search example is pretty representative.
RSS/Atom
We have pmxbot monitoring about a half dozen RSS feeds. The intranet and dev site both have them, we monitor twitter search for a bunch of keywords, as well as google news. It’s a pretty sweet feature, if you ask me.
In conclusion, pmxbot is awesome. I’d like to make it even easier for people to add their own features. Maybe include a setting in the YAML conf file that’s a python file which is imported? What else do you have (all zero of you using pmxbot)?
3 Comments »
Posted: March 12th, 2010 | Author: chmullig | Filed under: Nerdery | Tags: data, picloud, python | 2 Comments »
I had to crunch some data today, and decided to experiment a bit. It mostly involved lots and lots of Levenshtein ratios. On my laptop it took over 25 minutes to complete a single run (45k rows, several thousand calculations per row) – a bummer when you want to quickly iterate the rules, cutoffs, penalties, etc. First step was simply cutting out some work that was a nice-to-have. That got me down to 16 minutes.
Second was adding multiprocessing. I figured this would be easy, but the way I originally wrote the code (the function required both an element, and a penalty matrix) meant that just plain multiprocessing.Pool.map() wasn’t working. I wrapped it up with itertools.izip(iterator, itertools.repeat(matrix)), but that gives a tuple which you can’t easily export. It turns out that this, basically calculatorstar from the Pool example, is a godsend:
def wrapper(args):
return func(*args)
So that got me down to 8 minutes on my laptop. However the cool part is that on an 8 core server I was down to only 1 minute, 30 seconds. Those are the sorts of iteration times I can deal with.
Then I decided to try the PiCloud. After trying it out earlier this week I thought it would be interesting to test it on a real problem that linearly scales with more cores. They advertise it in the docs, so I figured maybe it would be useful and even faster. Not so fast. It was easy to write after I already had multiprocessing working, but the first version literally crashed my laptop. I later figured out that the “naive” way to write it made it suck up all the RAM on the system. After less than 5 minutes I killed it with 1.7GB/2GB consumed. Running it on the aforementioned 8 core/32GB server had it consume 5GB before it finally crashed with a HTTP 500 error. I posted in the forums, got some advice, but still can’t get it working. (Read that short thread for the rest of the story). This seems like exactly what they should be nailing, but so far they’re coming up empty.
2 Comments »
Posted: March 9th, 2010 | Author: chmullig | Filed under: Nerdery | Tags: distributed, picloud, pyro, python | 1 Comment »
A couple weeks ago my coworker mentioned PiCloud. It claims to be “Cloud Computing. Simplified.” for python programming. Indeed, their trivial examples are too good to be true, basically. I pointed out how the way it was packaging up code to send over the wire was a lot like Pyro‘s Mobile Code feature. We actually use Pyro mobile code quite a bit at work, within the context of our own distributed system running across machines we maintain.
After getting beta access I decided to check it out today. I spent about 15 minutes playing around with it, and decided to do a short writeup because there’s so little info out there. The short version is that technically it’s quite impressive. Simple, but more complicated than square(x) cases are as easy as they say. Information about PiCloud is in pretty short supply, so here’s my playing around reproduced for all to see.
Installing/first using
This is pretty easy. I’m using a virtualenv because I was skeptical, but it’s neat how easy it is even with that. So I’m going to setup a virtualenv, install ipython to the virtualenv, then install the cloud egg. At the end I’ll add my api key to the ~/.picloud/cloudconf.py file so I don’t need to type it repeatedly. The file is created when you first import cloud, and is very straightforward.
chmullig@gore:~$ virtualenv picloud
New python executable in picloud/bin/python
Installing setuptools............done.
chmullig@gore:~$ source picloud/bin/activate
(picloud)chmullig@gore:~$ easy_install -U ipython
Searching for ipython
#snip
Processing ipython-0.10-py2.6.egg
creating /home/chmullig/picloud/lib/python2.6/site-packages/ipython-0.10-py2.6.egg
Extracting ipython-0.10-py2.6.egg to /home/chmullig/picloud/lib/python2.6/site-packages
Adding ipython 0.10 to easy-install.pth file
Installing iptest script to /home/chmullig/picloud/bin
Installing ipythonx script to /home/chmullig/picloud/bin
Installing ipcluster script to /home/chmullig/picloud/bin
Installing ipython script to /home/chmullig/picloud/bin
Installing pycolor script to /home/chmullig/picloud/bin
Installing ipcontroller script to /home/chmullig/picloud/bin
Installing ipengine script to /home/chmullig/picloud/bin
Installed /home/chmullig/picloud/lib/python2.6/site-packages/ipython-0.10-py2.6.egg
Processing dependencies for ipython
Finished processing dependencies for ipython
(picloud)chmullig@gore:~$ easy_install http://server/cloud-1.8.2-py2.6.egg
Downloading http://server/cloud-1.8.2-py2.6.egg
Processing cloud-1.8.2-py2.6.egg
creating /home/chmullig/picloud/lib/python2.6/site-packages/cloud-1.8.2-py2.6.egg
Extracting cloud-1.8.2-py2.6.egg to /home/chmullig/picloud/lib/python2.6/site-packages
Adding cloud 1.8.2 to easy-install.pth file
Installed /home/chmullig/picloud/lib/python2.6/site-packages/cloud-1.8.2-py2.6.egg
Processing dependencies for cloud==1.8.2
Finished processing dependencies for cloud==1.8.2
(picloud)chmullig@gore:~$ python -c 'import cloud' #to create the ~/.picloud directory
(picloud)chmullig@gore:~$ vim .picloud/cloudconf.py #to add api_key and api_secretkey
Trivial Examples
This is their trivial example, just to prove it’s as easy for me as it was for them.
In [1]: def square(x):
...: return x**2
...:
In [2]: import cloud
In [3]: cid = cloud.call(square, 10)
In [4]: cloud.result(cid)
Out[4]: 100
BAM! That’s just stupidly easy. Let’s try a module or two.
In [5]: import random
In [6]: def shuffler(x):
...: xl = list(x)
...: random.shuffle(xl)
...: return ''.join(xl)
...:
In [8]: cid = cloud.call(shuffler, 'Welcome to chmullig.com')
In [9]: cloud.result(cid)
Out[9]: ' etcmmhmoeWll.cgcl uioo'
Less-Trivial Example & Packages
So that’s neat, but what about something I wrote, or something that’s off pypi that they don’t already have installed? Also quite easy. I’m going to be using Levenshtein edit distance for this, because it’s simple but non-standard. For our purposes we’ll begin with a pure python implementation, borrowed from Magnus Lie. Then we’ll switch to a C extension version, originally written by David Necas (Yeti), which I’ve rehosted on Google Code.
(picloud)chmullig@gore:~$ wget -O hetlev.py http://hetland.org/coding/python/levenshtein.py
#snip
2010-03-09 12:13:04 (79.2 KB/s) - `hetlev.py' saved [707/707]
(picloud)chmullig@gore:~$ easy_install http://pylevenshtein.googlecode.com/files/python-Levenshtein-0.10.1.tar.bz2
Downloading http://pylevenshtein.googlecode.com/files/python-Levenshtein-0.10.1.tar.bz2
Processing python-Levenshtein-0.10.1.tar.bz2
Running python-Levenshtein-0.10.1/setup.py -q bdist_egg --dist-dir /tmp/easy_install-mqtK2d/python-Levenshtein-0.10.1/egg-dist-tmp-igxMyM
zip_safe flag not set; analyzing archive contents...
Adding python-Levenshtein 0.10.1 to easy-install.pth file
Installed /home/chmullig/picloud/lib/python2.6/site-packages/python_Levenshtein-0.10.1-py2.6-linux-x86_64.egg
Processing dependencies for python-Levenshtein==0.10.1
Finished processing dependencies for python-Levenshtein==0.10.1
(picloud)chmullig@gore:~$
Now both are installed locally and built. Beautiful. Let’s go ahead and test out the hetlev version.
In [18]: def distances(word, comparisonWords):
....: results = []
....: for otherWord in comparisonWords:
....: results.append(hetlev.levenshtein(word, otherWord))
....: return results
In [24]: zip(words, distances(word, words))
Out[24]:
[('kitten', 0),
('sitten', 1),
('sittin', 2),
('sitting', 3),
('cat', 5),
('kitty', 2),
('smitten', 2)]
Now let’s put that up on PiCloud! It’s, uh, trivial. And fast.
In [25]: cid = cloud.call(distances, word, words)
In [26]: zip(words, cloud.result(cid))
Out[26]:
[('kitten', 0),
('sitten', 1),
('sittin', 2),
('sitting', 3),
('cat', 5),
('kitty', 2),
('smitten', 2)]
Now let’s switch it to use the C extension version of edit distance from the PyLevenshtein package, and try to use it with PiCloud.
In [32]: import Levenshtein
In [33]: def cdistances(word, comparisonWords):
results = []
for otherword in comparisonWords:
results.append(Levenshtein.distance(word, otherword))
return results
....:
In [38]: zip(words, cdistances(word, words))
Out[38]:
[('kitten', 0),
('sitten', 1),
('sittin', 2),
('sitting', 3),
('cat', 5),
('kitty', 2),
('smitten', 2)]
In [39]: cid = cloud.call(cdistances, word, words)
In [40]: cloud.result(cid)
ERROR: An unexpected error occurred while tokenizing input
The following traceback may be corrupted or invalid
The error message is: ('EOF in multi-line statement', (30, 0))
ERROR: An unexpected error occurred while tokenizing input
The following traceback may be corrupted or invalid
The error message is: ('EOF in multi-line statement', (37, 0))
---------------------------------------------------------------------------
CloudException Traceback (most recent call last)
CloudException: Job 14:
Could not depickle job
Traceback (most recent call last):
File "/root/.local/lib/python2.6/site-packages/cloudserver/workers/employee/child.py", line 202, in run
File "/usr/local/lib/python2.6/dist-packages/cloud/serialization/cloudpickle.py", line 501, in subimport
__import__(name)
ImportError: ('No module named Levenshtein', <function subimport at 0x2290ed8>, ('Levenshtein',))
Installing C-Extension via web
 Not too surprisingly that didn’t work – Levenshtein is a C extension I built on my local machine. PiCloud doesn’t really make it obvious, but you can add C-Extensions via their web interface. Amazingly you can point it to an SVN repo and it will let you refresh it. It seems to download and call setup.py install, but it’s a little unclear. The fact is it just worked, so I didn’t care. I clicked on “Add Repository” and pasted in the URL from google code, http://pylevenshtein.googlecode.com/svn/trunk. It built it and installed it, you can see the output on the right. I then just reran the exact same command and it works.
Not too surprisingly that didn’t work – Levenshtein is a C extension I built on my local machine. PiCloud doesn’t really make it obvious, but you can add C-Extensions via their web interface. Amazingly you can point it to an SVN repo and it will let you refresh it. It seems to download and call setup.py install, but it’s a little unclear. The fact is it just worked, so I didn’t care. I clicked on “Add Repository” and pasted in the URL from google code, http://pylevenshtein.googlecode.com/svn/trunk. It built it and installed it, you can see the output on the right. I then just reran the exact same command and it works.
In [41]: cid = cloud.call(cdistances, word, words)
In [42]: cloud.result(cid)
Out[42]: [0, 1, 2, 3, 5, 2, 2]
In [43]: zip(words, cloud.result(cid))
Out[43]:
[('kitten', 0),
('sitten', 1),
('sittin', 2),
('sitting', 3),
('cat', 5),
('kitty', 2),
('smitten', 2)]
Slightly more complicated
I’ve written a slightly more complicated script that fetches the qwantzle corpus and uses jaro distance to find the n closest words in the corpus to a given word. It’s pretty trivial and dumb, but definitely more complicated than the above examples. Below is closestwords.py
import Levenshtein
import urllib
class Corpusinator(object):
'''
Finds the closest words to the word you specified.
'''
def __init__(self, corpus='http://cs.brown.edu/~jadrian/docs/etc/qwantzcorpus'):
'''Setup the corpus for later use. By default it uses
http://cs.brown.edu/~jadrian/docs/etc/qwantzcorpus, but can by overridden
by specifying an alternate URL that has one word per line. A number, a space, then the word.
'''
raw = urllib.urlopen('http://cs.brown.edu/~jadrian/docs/etc/qwantzcorpus').readlines()
self.corpus = set()
for line in raw:
try:
self.corpus.add(line.split()[1])
except IndexError:
pass
def findClosestWords(self, words, n=10):
'''
Return the n (default 10) closest words from the corpus.
'''
results = {}
for word in words:
tempresults = []
for refword in self.corpus:
dist = Levenshtein.jaro(word, refword)
tempresults.append((dist, refword))
tempresults = sorted(tempresults, reverse=True)
results[word] = tempresults[:n]
return results |
Very simple. Let’s try ‘er out. First locally, then over the cloud.
In [1]: import closestwords
In [2]: c = closestwords.Corpusinator()
In [3]: c.findClosestWords(['bagel', 'cheese'], 5)
Out[3]:
{'bagel': [(0.8666666666666667, 'barge'),
(0.8666666666666667, 'bag'),
(0.8666666666666667, 'badge'),
(0.8666666666666667, 'angel'),
(0.8666666666666667, 'age')],
'cheese': [(1.0, 'cheese'),
(0.95238095238095244, 'cheesed'),
(0.88888888888888895, 'cheers'),
(0.88888888888888895, 'cheeks'),
(0.8666666666666667, 'cheeseball')]}
Unfortunately it just doesn’t want to work happily with PiCloud & ipython when you’re running import closestwords. The most obvious won’t work, cloud.call(c.findClosestWords, [‘bagel’]). Neither will creating a tiny wrapper function and calling that within ipython:
def caller(words, n=10):
c = closestwords.Corpusinator()
return c.findClosestWords(words, n)
cloud.call(caller, ['bagel']) |
I created a stupidly simple wrapper python file, wrap.py:
import closestwords
import cloud
cid = cloud.call(closestwords.caller, ['bagel',])
print cloud.result(cid) |
That gives an import error. Even putting that caller wrapper above at the bottom of the closestwords.py and calling it in the __main__ section (as I do below with c.findClosestWords) didn’t work.
However if I stick it directly in closestwords.py, initialize the instance, then run it from there, everything is fine. I’m not sure what this means, if it’s supposed to happen, or what. But it seems like it could be a pain in the butt just to get it calling the right function in the right context.
if __name__ == '__main__':
import cloud
c = Corpusinator()
cid = cloud.call(c.findClosestWords, ['bagel',])
print cloud.result(cid) |
What passes for a conclusion
I had a good time playing with PiCloud. I’m going to look at adapting real code to use it. If I get carried away AND feel like blogging I’ll be sure to post ‘er up. They have pretty good first tier support for the map part of map/reduce, which would be useful. Two links I found useful when working with PiCloud:
Update 3/11
Aaron Staley of PiCloud wrote me a nice email about this post. He says my problem with the closestwords example was due to a server side bug they’ve fixed. In playing around, it does seem a bit better. A few ways I tried to call it failed, but many of them worked. I had trouble passing in closestwords.caller, either in ipython or the wrapper script. However re-defining caller in ipython worked, as did creating an instance and passing in the instance’s findClosestWords function. A+ for communication, guys.
In [3]: cid = cloud.call(closestwords.caller, ['bagel'])
In [4]: cloud.result(cid)
ERROR: An unexpected error occurred while tokenizing input
The following traceback may be corrupted or invalid
The error message is: ('EOF in multi-line statement', (30, 0))
ERROR: An unexpected error occurred while tokenizing input
The following traceback may be corrupted or invalid
The error message is: ('EOF in multi-line statement', (37, 0))
---------------------------------------------------------------------------CloudException: Job 36: Could not depickle job
Traceback (most recent call last):
File "/root/.local/lib/python2.6/site-packages/cloudserver/workers/employee/child.py", line 202, in run
AttributeError: 'module' object has no attribute 'caller'
In [8]: c = closestwords.Corpusinator()
In [9]: cid = cloud.call(c.findClosestWords, ['bagel', 'cheese'], 5)
In [10]: cloud.result(cid)
Out[10]:
{'bagel': [(0.8666666666666667, 'barge'),
(0.8666666666666667, 'bag'),
(0.8666666666666667, 'badge'),
(0.8666666666666667, 'angel'),
(0.8666666666666667, 'age')],
'cheese': [(1.0, 'cheese'),
(0.95238095238095244, 'cheesed'),
(0.88888888888888895, 'cheers'),
(0.88888888888888895, 'cheeks'),
(0.8666666666666667, 'cheeseball')]}
In [11]: def caller(words, n=10):
....: c = closestwords.Corpusinator()
....: return c.findClosestWords(words, n)
....:
In [12]: cid = cloud.call(caller, ['bagel'])
In [13]: reload(closestword)
KeyboardInterrupt
In [13]: cloud.result(cid)
Out[13]:
{'bagel': [(0.8666666666666667, 'barge'),
(0.8666666666666667, 'bag'),
(0.8666666666666667, 'badge'),
(0.8666666666666667, 'angel'),
(0.8666666666666667, 'age'),
(0.8222222222222223, 'barrel'),
(0.8222222222222223, 'barely'),
(0.81111111111111123, 'gamble'),
(0.79047619047619044, 'vaguely'),
(0.79047619047619044, 'largely')]}
Update 3/12
I did some more experimentation with PiCloud, posted separately.
1 Comment »